Jamstack应用程序使用连接池连接PostgreSQL的优势
要构建现代 Web 应用程序,如何使用 PostgreSQL 作为我们的数据库来使用我们的 Jamstack 应用程序所需的数据,使用 Next.js 构建一个应用程序,然后使用 PostgreSQL 通过连接池来提供数据。

今天,要构建现代 Web 应用程序,我们需要一个体面的数据库来提供我们的应用程序数据。有很多数据库可供我们选择。在这篇文章中,我们将学习如何使用 PostgreSQL 作为我们的数据库来使用我们的 Jamstack 应用程序所需的数据。
什么是 Jamstack?
“基于客户端 JavaScript、可重用 API 和预构建标记的现代 Web 开发架构。” – Mathias Biilmann(Netlify 的首席执行官兼联合创始人)
Jamstack 一词代表JavaScript、API 和标记,它是构建我们应用程序的现代方式。Jamstack 应用程序将代码(应用程序)、基础设施 (API) 和内容(标记)拆分在一个解耦架构中处理,这意味着服务器端和客户端之间存在分离。
可以构建通过 CDN 统计服务的整个应用程序,而不是运行生成动态内容的整体后端。但是这个应用程序是基于 API 的,理想情况下会带来更快的体验。
我们可以使用几个出色的性能框架来利用 Jamstack 的优势。其中一些引人注目的是Remix、SevelteKit、Nuxt、Next、11ty、Gatsby和Astro。
我们将使用 Next.js 构建一个简单的应用程序,然后使用 PostgreSQL 通过连接池来提供数据。
使用 Next.js 设置项目
我们将使用 CLI 设置一个空白的 Next.js 项目。这将创建一个预配置的应用程序。
npx create-next-app@latest --typescript
让我们为应用程序命名nextjs-pg-connection-pool,然后添加必要的依赖项以开始查询我们的 Postgres 数据库。
npm i pg @types/pg
连接数据库
我们将连接到本地 Postgres 数据库并查询所需的数据。让我们使用 CLI 并输入以下内容:
psql Postgres
接下来,创建一个新的 Postgres 数据库实例以与我们在本地计算机中的数据库进行交互并列出。您还可以使用 AWS、Heroku 或 GCP 提供的免费 Postgres 数据库,并使用提供给您的连接字符串进行连接。
CREATE DATABASE employeedb
\l
我们可以成功看到我们刚刚创建的数据库的名称。
为了让我们开始通过我们的应用程序查询数据库,我们需要连接我们的应用程序和本地 Postgres 数据库。有多种方法可以做到这一点,例如使用开源库,如 pgbouncer、pgcat、pgpool 等。
在本文中,我们将使用最流行的 Postgres 连接客户端之一,称为node-postgres,这是一个用纯 JavaScript 编写的 Node.js 的非阻塞 PostgreSQL 客户端。
当客户端连接到 PostgreSQL 数据库时,服务器会派生一个进程来处理连接。我们的 PostgreSQL 数据库有一个固定的最大连接数,一旦达到限制,其他客户端将无法连接。
每个活动连接消耗大约 10MB 的 RAM。我们可以通过连接池来克服这些潜在问题。
让我们看看两种方法:
- 在没有连接池的情况下连接到本地 Postgres 数据库
- 使用连接池,它可以让我们管理集群中每个数据库可用的进程数。通过使用具有不同进程限制的多个连接池,我们可以根据需求对数据库进行优先级排序
使用 PostgreSQL 的连接池
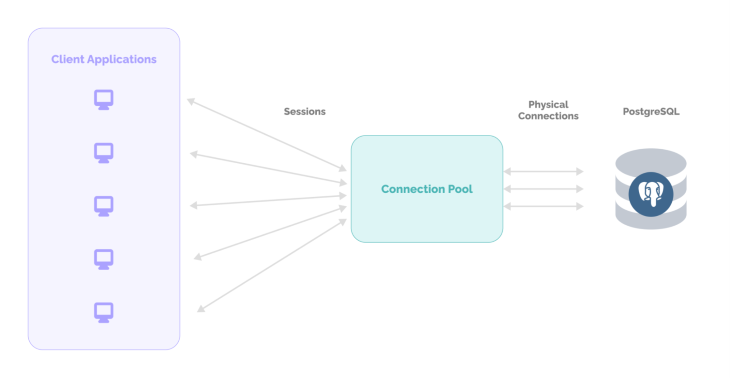
连接池是创建连接池并缓存这些连接以便它们可以再次重用的方法。这是在查询请求之前处理数据库连接的最常用方法之一。
我们通常认为数据库连接速度很快,但是当我们需要连接大量客户端时,情况并非如此。连接最多需要 35-50 毫秒,但如果我们通过连接池方法进行连接,则只需 1-2 毫秒。通过连接池,我们预先分配数据库连接并在新客户端连接时回收它们。
连接池的选项
连接池有几种主要类型:框架连接池、独立连接池和持久连接。但是,持久连接池实际上只是充当连接池策略的一种解决方法。
1.框架连接池
框架连接池发生在应用程序级别。当我们希望我们的服务器脚本启动时,会建立一个连接池来处理稍后到达的查询请求。但是,这可能会受到连接数量的限制,因为它可能会遇到大量内存使用。
2. 独立连接池
当我们分配 5MB-10MB 的开销内存来满足请求查询时,我们称之为独立连接池。它是针对 Postgres 会话、语句和事务进行配置的,使用此方法的主要好处是每个连接的最小开销成本约为 2KB。
3. 持久连接池
这种类型的连接池使初始连接从初始化时就处于活动状态。它提供了不错的连续连接,但不完全具备连接池功能。
它对于连接开销通常在 25-50 毫秒之间的一小组客户端最有帮助。这种方法的缺点是它仅限于多个数据库连接,通常每个条目只有一个连接到服务器。
准备我们的数据以进行池化
至此,我们已经在本地创建了一个新数据库并将其命名为employeedb。但是我们里面没有任何数据。让我们编写一个简单的查询来创建一个员工表:
CREATE TABLE IF NOT EXISTS employees(
id SERIAL PRIMARY KEY,
name VARCHAR(100) UNIQUE NOT NULL,
designation VARCHAR(200),
created_on TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP
);
我们还需要将数据添加到我们创建的表中:
INSERT INTO employees (name, designation)
VALUES
('Ishan Manandhar', 'Designer and Developer'),
('Jane Doe', 'JamStack Developer'),
('Alfred Marshall', 'Content Writer'),
('John Doe', 'Product Designer'),
('Dave Howard', 'Security Analyst');
SELECT * FROM employees;
现在,我们可以在 Next 项目中创建一个新目录并调用它employeeold
../src/pages/api/employeeold
// creating a new connection and closing connection for each request
import type { NextApiRequest, NextApiResponse } from 'next';
import { Client } from "pg";
const employeeOld = async (req: NextApiRequest, res: NextApiResponse) => {
const client = new Client({
host: "localhost",
user: "postgres",
password: "postgres",
database: "employeedb",
port: 5432,
});
client.connect();
const { method } = req;
if (method === 'GET') {
try {
const query = await client.query('SELECT * FROM employees');
res.status(200).json(query.rows);
client.end();
return
}
catch (err: any) {
res.status(404).json({ message: 'Error: ' + err.message });
}
}
else {
res.status(404).json({ message: 'Method Not Allowed' });
}
client.end();
}
export default employeeOld;
在这里,我们创建了一个新端点,可以查询数据库中的所有员工列表。我们实现了一种正常的查询请求方式来建立与我们的数据库的连接,而不使用池。
我们使用 pg-pool 来创建一个新的连接,每次我们点击这个 API 时都会建立这个连接。每次客户端请求数据时,我们也会关闭我们打开的连接。
以下是发生连接时涉及的步骤:
- 打开到数据库的新连接
- 在数据库上对用户进行身份验证
- 打开一个 TCP 套接字用于读取和写入数据
- 通过套接字读取和写入数据
- 关闭连接
- 关闭套接字
每次用户请求数据时连接到数据库的 Web 应用程序将需要几毫秒的延迟响应。但是当我们提出一个巨大的请求时,它可能需要更长的时间,特别是如果这些请求是同时发送的。此连接会消耗服务器的资源,这可能会导致数据库服务器过载。
最佳实践是提前创建固定数量的数据库连接,并将它们重用于不同的任务。当任务多于连接数时,应该阻塞它们,直到有空闲连接。这就是连接池发挥作用的地方。
注意:这可能不是连接池的理想情况。您可以改为getStaticProps在我们的下一个应用程序中获取此数据,但在本文中,我们只想演示使用 Next.js 的连接池。
使用连接池
node-postgres 库通过pg-pool模块提供了内置的连接池。在创建新池期间,我们需要传入一个可选config对象。当池创建客户端时,这将传递给池(并传递给池中的每个客户端实例)。
我们将遍历传递给配置对象的每个字段。您可以在此处找到文档。
connectionTimeoutMillis: 与新客户端建立连接时超时前等待的毫秒数。默认情况下,超时设置为0max:池应包含的最大客户端数,10默认设置为idleTimeOutMillis:这是指客户端需要在池中闲置的毫秒时间。在它与后端断开连接并被忽略之前,它不会被检出。默认时间设置为10,但我们可以将其设置0为禁用空闲客户端的自动断开连接allowExitOnIdle: 一个布尔属性,当设置为时true,将允许节点事件循环在池中的所有客户端空闲时立即退出,即使它们的套接字仍然打开。当我们不想在我们的进程退出之前等待我们的客户空闲时,这会派上用场
让我们在api文件夹中创建一个新文件并将其命名employeenew,该api文件夹与我们的下一个预配置设置文件夹一起提供./src/pages/api/employeenew:
import type { NextApiRequest, NextApiResponse } from 'next';
import { Pool } from "pg";
let connection: any;
if (!connection) {
connection = new Pool({
host: "localhost",
user: "postgres",
password: "postgres",
database: "employeedb",
port: 5432,
max: 20,
connectionTimeoutMillis: 0,
idleTimeoutMillis: 0,
allowExitOnIdle: true
});
}
const employeeNew = async (req: NextApiRequest, res: NextApiResponse) => {
const { method } = req;
if (method === 'GET') {
try {
const query = await connection.query('SELECT * FROM employees');
return res.status(200).json(query.rows);
}
catch (err: any) {
res.status(404).json({ message: 'Error: ' + err.message });
}
}
else {
res.status(404).json({ message: 'Method Not Allowed' });
}
}
export default employeeNew;
在这里,我们创建了一个新端点,可以查询数据库中的所有员工列表,并实现了连接池机制。我们预先打开了 20 个连接,这样我们就可以避免连接打开和关闭的时间延迟问题。
性能比较
我们已经实现了两种连接机制来连接我们的 Postgres 数据库。我们为演示目的实现了独立池,我们在其中分配了一些最大连接,释放了对传入请求的侦听和预分配的连接。当我们创建连接池类时,我们应该满足以下几个因素来提高数据库性能:
- 预先分配连接
- 监督可用的连接
- 分配新连接
- 等待连接可用
- 关闭连接
注意:在我们一次创建大量并发请求之前,我们可能不会看到性能上有显着差异。
为了在浏览器内部进行测试,我们将打开我们的开发者工具并添加这行代码:
for (let i = 0; i < 2000; i++) fetch(`http://localhost:3000/api/employeesOld`).then(a=>a.json()).then(console.log).catch(console.error);
我们还需要用另一条路由测试我们的连接性能。
for (let i = 0; i < 2000; i++) fetch(`http://localhost:3000/api/employeesNew`).then(a=>a.json()).then(console.log).catch(console.error);
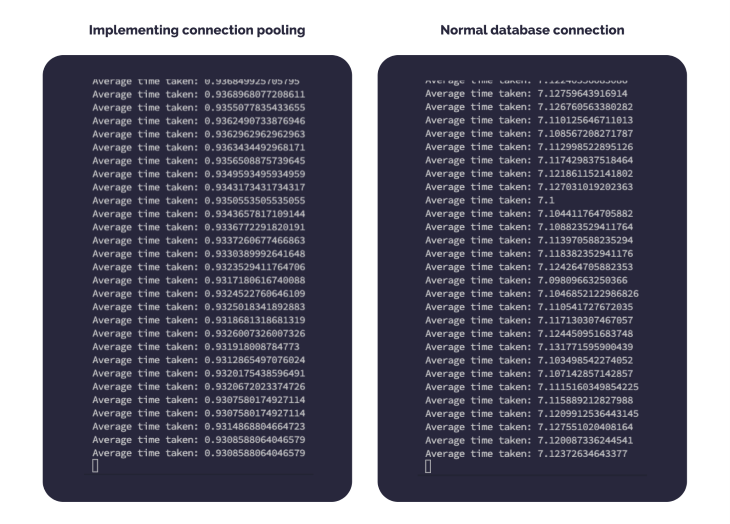
这是一个快照,显示了这两种方法的性能比较。
为什么应该使用连接池
使用连接池有很多好处,尤其是在建立复杂连接时。例如,与新客户端的连接可能需要 20-30 毫秒,其中协商密码、建立 SSL 以及与客户端和服务器共享配置信息,所有这些都会大大降低我们的应用程序性能。
您还应该记住,PostgreSQL 一次只能在一个连接的客户端上以先进先出的方式处理一个查询。如果我们有一个使用单个连接客户端的多租户应用程序,来自所有同时请求的所有查询都将排在一个队列中并一个接一个地连续执行,这会大大降低性能。
最后,根据可用内存,PostgreSQL 一次只能处理有限数量的客户端。如果我们连接无限数量的客户端,我们的 PostgreSQL 甚至可能崩溃。
何时在 PostgreSQL 中使用连接池
使用连接池将会非常有帮助,如果我们的数据库:
- 处理大量空闲连接
- 由于最大连接限制而断开连接
- 当需要同时在多个用户之间共享连接时
- 由于高 CPU 使用率导致的性能问题
- 提高连接速度
- 节省资源和金钱
总结
打开我们的数据库连接是一项昂贵的操作。 在我们构建的现代 Web 应用程序中,我们倾向于打开许多连接,这会导致资源和内存的浪费。
连接池是一项基本功能,可确保关闭的连接不会真正关闭,而是返回到池中,并且打开新连接会返回相同的物理连接,从而减少数据库上的分叉任务。
借助连接池,我们可以减少数据库在给定时间内必须处理的进程数。 这样可以释放连接我们数据库所需的资源,提高连接数据库的速度